Chapter 7 - Trees,Heaps,Hash table
Binary Tree
properties
- a structure that consists of nodes who each have 0,1,2 children
- the children are called left and right
- a node is the parent of its children
- a childless node is called a leaf , and the other nodes are internal nodes
- a binary tree has at most one mode that has no parent, i.e. root
- the descendants of each node form the subtree of the binary tree with node as the root
- The height of a node in a binary tree is the length of the longest simple downward path from the node to a leaf
- the edges are counted into the height, the height of a left is 0 ;
- the height of a binary tree is the height of it’s root
- a binary tree is completely balanced
- if the difference between the height of the root’s left and right subtree is atmost one and the subtrees are compleletly balanced
Traversal order of the tree
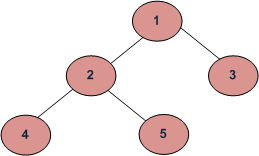
PREORDER(中左右) : 1,2,4,5,3 INORDER(左中右):4,2,5,1,3 POSTORDER(左右中) :4,5,2,3,1
PRE,IN,POST 意味住個root嘅處理次序
PREORDER-TREE-WALK(x)
if x!=NULL then
process the elemment x
PREORDER-TREE-WALK(x->left)
PREORDER-TREE-WALK(x->right)
INORDER-TREE-WALK(x)
if x!=NULL then
INORDER-TREE-WALK(x->left)
process the elemment x
INORDER-TREE-WALK(x->right)
POSTORDER-TREE-WALK(x)
if x!=NULL then
POSTORDER-TREE-WALK(x->left)
POSTORDER-TREE-WALK(x->right)
process the elemment x
Running Time: $\Theta(n)$
Extra Memory Conumpstion = $\Theta$(Maximum recusion depth) = $\Theta(h+1)$ = $\Theta(h)$
Binary Search Tree
- to satisfy
 $\text{Let l be any node in the left subtree of the node x and r be any node in right subtree of x then}$
$\text{Let l be any node in the left subtree of the node x and r be any node in right subtree of x then}$
$l.key \leq x.key \leq r.key$
- Usually a binary tree is represented by a linked structure where each object contains the fields $key,left, right, parents$
- Can use Inorder Traversal to traval all the nodes with ascending order
TREE-SEARCH(x,k)
while x!= NULL and k != x->key do //until the key is found
if k < x->key then // the searched key is smaller
x:= x->left
else // the searched key is larger
x:= x->right
return x;
R-TREE-SEARCH(x,k)
if(x == NIL or k == x->key ) then // the base case
return x;
if(k < x->key) then // the searched key is smaller
return R-TREE-SEARCH(x->left,k)
else
return R-TREE-SEARCH(x->right,k)
Iterative
- Running Time $O(h)$
- Extra Memory Requriement $ \Theta(1) $
Recusive
- Running Time $O(h)$
- Memory Requriement $O(h)$
TREE-MINIMUM(x)
while x->left != NULL do
x:= x->left
return x
TREE-MAXIMUM(x)
while x->right != NULL do
x:= x->right
return x
Successor of the node is either
- the smallest element in the right subtree, if the node has right subtree
- the first element on the path to the root whose left subtree contains a given node ` //if the node doesn’t have right subtree

TREE-SUCCESSOR(x)
if x->right != NIL then // there is a right subttree
return TREE-MINIMUM(x->right)
y:= x->p //step forward to the root
while y!= NIL and x=y->right // until we've moved out of the left child
x:= y
y:y->p
return y // return the found node
TREE-SCAN-ALL(T)
if T.root != NIL then //直接跳到minimum
x:= TREE-MINIMUM(T.root)
else
x:= NIL
while x!=NIL do
process the element x
x:= TREE-SUCCESSOR(x);
TREE-INSERT(T,z) //z points to a structure allocated by the user)
y:=NIL; x:= T.root //start from the root
while x!= NIL do //go downwards until an empty spot is located
y:= x //save the potential parent
if z->key < x->key then
x:= x->left
else
x:x->right
z->p := y //make the node found the parent of the new one)
if y=NIL then
T.root := z // the root is the only node in the tree
else if z->key < y->key //make the new node its parent left
y->left := z
else //right child
y->right := z
z->left := NIL , z->right := NIL
- the Algorithm traces a path from the root down to a leaf , a new node is always placed as a leaf.
TREE-DELETE
http://alrightchiu.github.io/SecondRound/binary-search-tree-sortpai-xu-deleteshan-chu-zi-liao.html
Heap
An array A[1….n] is a heap, if $A[i] \geq A[2i]$ and $A[i] \geq A[2i+1]$ always when $1 \leq i \leq |\frac{n}{2}|$ and ($2i+1 \leq n$)

- the value of each node is larger or equal to the values of its children
PARENT(i)
return i/2
LEFT(i)
return 2i;
RIGHT(i)
return 2i+1
HEAPIFY(A,i) //i is the element where the element might be too small
repeat // repeat until the heap is fixed
old_i := i; // store the value of i
l = LEFT(i);
r:= RIGHT(i);
// the left child is lager than i
if l<= A.heapsize && A[l]>A[i] then
i=l;
// the right child is lager than i
if r<= A.heapsize && A[r] >A[i] then
i=r;
// We only choose the larger child
if i != old_i then // if a larger child is found
exchange A[old_i] <-> A[i]
until i = old_i; // do not wap
Building a Heap
BUILD-HEAP(A)
A.heapsize := A.length //(the heap is built out of the entire array)
for i:= n(A.length/2) down to 1 do //(scan through the lower half of the array )
HEAPIFY(A,i) //(call Heapify)

Sorting with a heap
HEAPSORT(A)
BUILD-HEAP(A) //covert the array into the a heap
for i:= A.length downto 2 do //scan the array from the last to the first element
exchange A[1] <-> A[i] //move the heap's largest element to the end
A.heapsize := A:heapsize.-1//move the largest element outside the heap
HEAPIFY(A,1) //fix the heap, which is otherwise fine

Heapsort Efficiency:
- BUILD_HEAP: $\Theta (n)$
- FOR-LOOP : n -1 times
-
HEAPIFY : $\Omega(n)$ and $O(logn)$
- HEAPSORT efficiney will be : $ \Omega(n)$ and $O(nlogn)$
Priority Queue
- is a data structure for maintaining a set $S$ of elements, each associated with a key value.
- Insert($S,x$) , insert element $x$ into the set $S$
- MAXIMUM($S$)
- EXTRACT-MAX($S$), remove and returns the element with largest key
- Can be used
- Prioritizing tasks in an opeartion system
- action based simulation
- finding the shortest route on a map
HEAP-MAXIMUM(A)
if A.heapsize < 1 then
error "heap underflow"
return A[1];
HEAP-EXTRACT-MAX(A)
if A.heapsize < 1 then
error "heap underflow"
max := A[1]
A[1]:= A[A.heapsize]
A.heapsize := A.heapsize - 1
HEAPFIY(A,1)
return max;
HEAP-INSERT(A,key)
A.heapsize:= A.heapsize + 1;
i = A.heapsize
while i > 1 and A[PARENT[i] < key] do
A[i] = A[PARENT[i]]
i := PARENT(i)
A[i]:=key;

Hash Table

-
reduce the range of possible key values in dynamic set by using a *hash function h* , so that the keys can be stored in an array
- effciency, constant-time indexing
- Reducing the range of keys creates a problems
- collision
- more than one element can hash into the same slot in the hash table
- solution
- chaining
- elements that hash to the same slot are put into a linked list
- chaining
- collision
- Running Time
- addtion : $\Theta(1)$
- Search: worst-case $\Theta(n)$
- removal: doubly-linked $\Theta(1)$, Singly linked list worst-case $\Theta(n)$
- The average running-times of the operations of a chained hash table depend on the lengths of the lists.
- The worst-case all elements in the same list , then will be $\Theta(n)$
- $m$ is the size of hash table
- $n$ is the amount of elements in the table
- $a=\frac{n}{m}=loadfactor$ the average lenth of the list
- average-case —> need estimate the hash function $h$
- Good Hash function
- It must be deterministic
- The hash function is as random as possible
- Methods for creating hash function
- division method
- $\text{h(k) = k mod m}$, where k is the key , m is the size of the hash table
- Multiplication Method
- $A=0.61803$
- h(k)=⌊m(kA−⌊kA⌋)⌋ ,
- kA−⌊kA⌋ means 取小數部分
- division method